Copy-on-Write
有些数据库没有使用复杂的锁机制而是使用了 copy-on-write 写时复制的技术来保证并行访问时的数据完整性。不管页的数据是如何被修改的,都会将他的内容复制出来,然后再新的页上进行更改,而不会对原有的页产生变更,这时一个并行的树的层次就会被创建出来。
旧的树版本仍然可以被读取跟写入进行并发的访问,当写入者访问被修改过的页时,他需要等待之前的写入操作完成。在新的页层次被创建后,指向最新页的指针会被原子性的更新。在 Figure 6-1 中可以看到新的树以并行的方式创建出来,并能够继续使用未被修改的页。
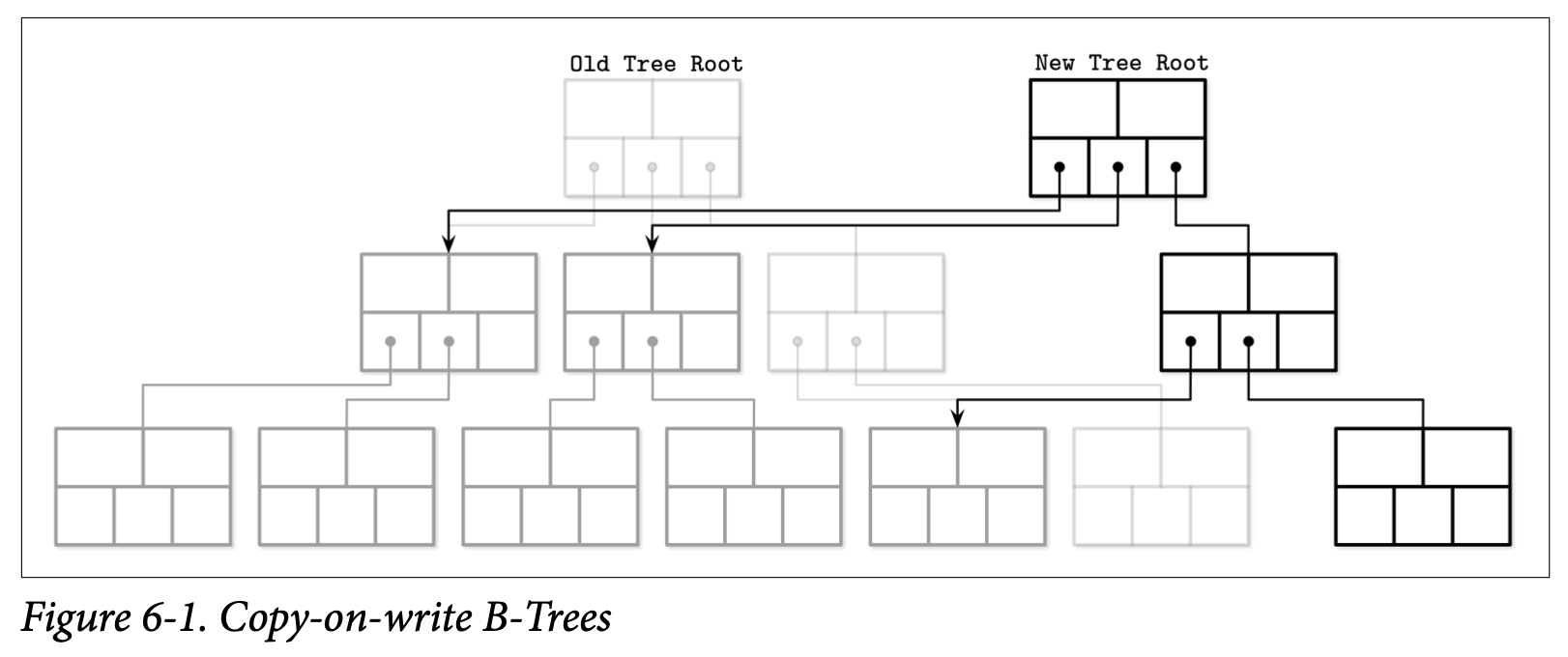
这种实现方式最明显的缺点就是需要更多的空间 (尽管旧的版本能够在短暂的时间内被回收,因为页可以在他上面的并发操作都完成后进行回收) 及更多的处理器耗时,因为整个页的内容都需要进行复制。因为 B-Tree 通常都很浅,这种方式的简单性跟优点常常大于他的缺点。
其中最大的优点在于读取操作不需要任何同步机制,因为页的写入是不可变的,并且可以在无需任何锁的情况下进行写入;因为写入操作是使用了复制的页,因此读取不会堵塞写入。也没有任何一个操作会观察到页的不完全的状态,系统的崩溃也不会导致页处于损坏的状态,因为最顶层的指针只有在所有的页修改都完成后才会进行变更。
Implementing Copy-on-Write: LMDB
一个使用了写时复制的存储引擎是 Lightning Memory-Mapped Database (LMDB),他是一个在 OpenLDAP 项目中使用的键值对存储引擎,基于他的设计跟架构,LMDB 不需要依赖于页缓存、预写日志、检查点或压缩等技术。
LMDB 使用了一个单层的数据存储,这表示读取跟写入的操作可以直接通过 Memory Map 内存映射来完成,而无需额外的应用程序级别的缓存。这同时也意味着页不需要额外的抽象,可以从内存映射中直接进行读取而无需将数据复制到其他的中间缓冲中。在更新时,从根节点到叶子节点路径中的所有分支的节点都需要被复制跟可能被修改:更新跟修改导致的传播路径上的节点会被更改,其余的则保持不变。
LMDB 只保存了根节点的两个版本:最新的版本,以及即将提交新变化的版本。因为所有的写入操作都会经过根节点,所以这已经足够了。在新的根被创建后,旧的那个对新的读取跟写入来说已经是不可用的了。在旧树的读取操作都完成后,他们的页将会被回收跟重新使用,因为 LMDB 只添加的设计,他不需要使用邻接节点,而是通过回溯到父节点来实现顺序扫描。
在这是个设计中,让脏数据留在复制后的节点是不现实的:因为已经有了可用于支持 MVCC 跟满足进行中的读取事务的副本。数据库的结构是支持多版本的,并且读取者能够在无需任何锁的前提下进行访问,因为他们不会对写入者有任何干扰。