Disk-Based Structures
我们已经在比较通用的层面上讨论过基于内存及基于磁盘的存储了。现在可以来具体的描绘一下具体数据结构之间的差异:有一些适合使用在磁盘,有一些则更适合使用于内存中。
就像我们讨论过的,不是所有满足空间跟复杂度的数据结构都能够高效的应用在基于磁盘的存储上。数据库中的数据结构需要能够适配持久化介质所带来的限制。
保存在磁盘中的数据结构通常用于处理那些数据量巨大,没办法将整个数据集存放到内存的情形。只有一部分的数据能够缓存在内存中,然后其他的则以能够高效访问的形式存储在磁盘中。
Hard Disk Drives
大部分传统的算法都是在流行以机械硬盘作为持久化存储介质时期开发的,他们的设计深受那个时代的影响。在之后新的存储介质被开发出来了,如闪存,这又启发了一系列新的算法的产生,也促使旧的算法进行了很多的调整,来适配这些新的硬件。到了现在,又出现了许多新的、优化来支持新的非易失性、字节寻址的存储设备的数据结构。(比如 XIA17 跟 KANNAN18)
对于机械硬盘来说,随机读取会因为寻址而提高性能开销,因为他们需要硬盘进行转动好让机械磁头能够移动到对应的位置来进行读写。然而,在这部分昂贵的操作完成之后,进行的顺序读取跟写入相对来说都是开销比较小的。
在机械硬盘中最小的传输单位是 sector 扇区,所以当对其进行操作时,最少会对一个扇区进行读或者写。扇区的尺寸一般会在 512 个字节跟 4Kb 之间。
磁头的定位是 HDD 硬盘操作中最为昂贵的一步。这也是为什么我们一直听到 Sequential I/O 顺序性 I/O 操作更好的原因: 连续性的从磁盘读取跟写入数据。
Solid State Drives
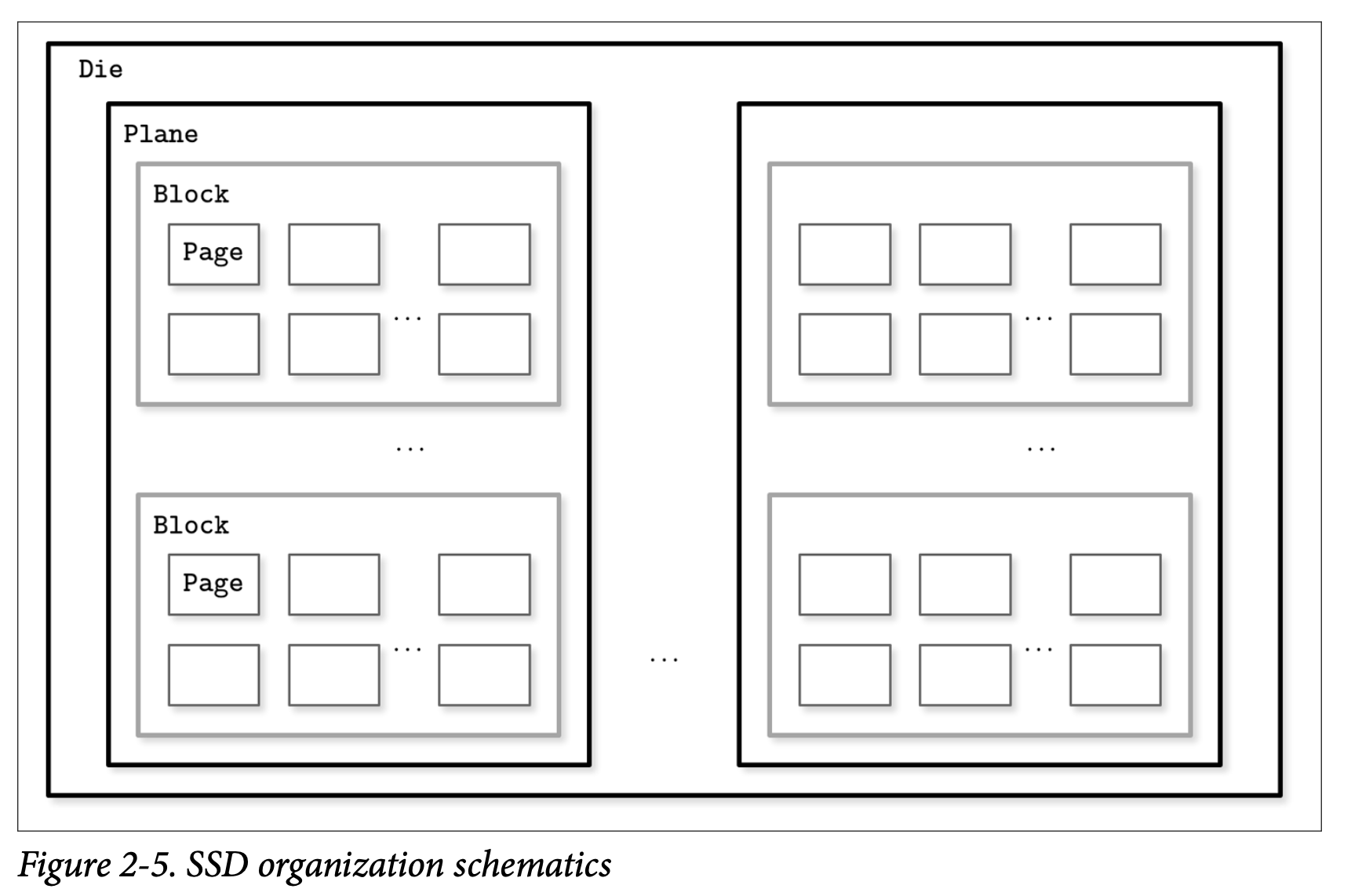
固态硬盘 (SSD) 没有需要移动的部分: 那里没有磁盘的转动,也没有磁头需要因为读取产生的定位操作。通常的 SSD 是使用 memory cells 内存单元组成的,他们连接成 strings (通常是 32 到 64 个内存单元构成一个 string),strings 又会组成 arrays 数组,数组再组成 pages 页面,最后由页面组成 blocks 块。
取决于具体使用的技术,一个内存单元可以存储一个或多个位的数据。设备之间的页面大小也可能是不同的,但一般来说他们的大小都会在 2 到 16Kb 之间,块则通常包含 64 到 512 个页面。块会组成 planes 平面,然后最后平面会被存放在 die 中。一个 SSD 可以有一个或多个的 die。Figure 2-5 展示了他们之间的层次关系
在 SSD 中进行读写的最小单位是页。但是,我们只能改变空的内存单元 (比如在写之前要先清除某个区域)。最小 erase 清除的单位不是页,而是包含了多个页的块,所以经常会将其称为 erase block 清除块。在一个空的块中可以对其页面进行顺序的写入。
其中有个内存控制器负责将页 ID 映射为物理位置,跟踪空白的区域,写入跟丢弃页面,这个控制器称为 Flash Translation Layer (FTL) 闪存翻译层。当 FTL 发现一个块可以安全的清除时,他还会负责进行垃圾回收的工作。有些块可能会有部分存活的页,在这种情况下,他会将这些块中存活的页面分配到新的位置,然后为他的页 ID 重新进行映射到新的位置。在这之后,他会清除那些现在已经没在使用的块,让他们可以支持后续新的写入操作。
因为两种设备类型 (HDD 跟 SSD) 都是使用地址来操作大块的数据,而不是操作独立的字节 (比如按块来访问数据),所以当今大部分的操作系统都为基于块设备进行了抽象。他们隐藏了内部的磁盘结构跟缓冲 I/O 操作,所以当我们从基于块的设备中读取单个 word 字时,其实整个块都会被包含在当次读取中。这是一个我们在使用磁盘数据结构是需要时刻考虑的限制。
在使用 SSD 时我们不需要像使用 HDD 一样将随机 I/O 跟 顺序 I/O 的区别看得那么重,因为随机跟顺序的读取延迟并没有太大的差别。但其中仍有一些由预读取、读取连续页面跟内部并行性引起的区别。
尽管垃圾回收通常在后台运行,但他仍然可能会对写操作造成负面的影响,特别是处理随机跟未对齐的写负载。
写入只会按照整个块来进行,并会将连续的写操作合并写到同一个块,这能够减少所需的 I/O 操作。我们会在后续的章节中讨论使用缓冲跟不变性会用来达到这个目标。
On-Disk Structures
除了磁盘访问本身的代价之外,构建高效的基于磁盘的数据结构的主要限制跟设计的条件主要来自于对磁盘的最小操作单位是块。要根据指针定位到具体某个块中的位置,我们需要将整个块都读出来。因为无论如何我们都需要这样做,因此可以通过调整数据结构的布局来利用这个特性。
我们已经在之前的章节中数次提到过指针,但这个词在基于磁盘的数据结构中的语义与之前稍有不同。在磁盘中,大部分时间我们都需要手动管理数据的布局 (除了使用 Memory Mapped File 技术时不需要)。这依然跟普通的指针操作类似,但我们需要自己来计算目标指针的地址并显式的跟随指针。
大部分时间磁盘上的偏移量是预先计算好的 *(避免指针所指向的区域在指针被写入磁盘之后还未写入磁盘)*又或者会缓存在内存中直到指向的区域都被写入磁盘。创建一个有长依赖链条的磁盘数据结构会大幅提高代码跟数据结构本身的复杂度,因此会倾向于将指针的数量跟其指向的范围控制到最小。
总而言之,基于磁盘的数据结构的设计会考虑其目标存储的细节,并将磁盘的访问次数优化到最少。我们可以通过提高局部性、优化数据结构内部的表现形式跟减少页外指针的数量来得到优化效果。
在 Binary Search Trees 一节中,我们总结出了高扇出跟低高度是设计基于磁盘的数据结构时达成优化的重要属性。我们还额外的空间开支来自于指针,以及为了保持树平衡而带来的管理这些指针的开支。B-Trees 组合了这些想法:提高节点的扇出量,降低树的高度、节点的指针数以及维持树平衡操作的频率。
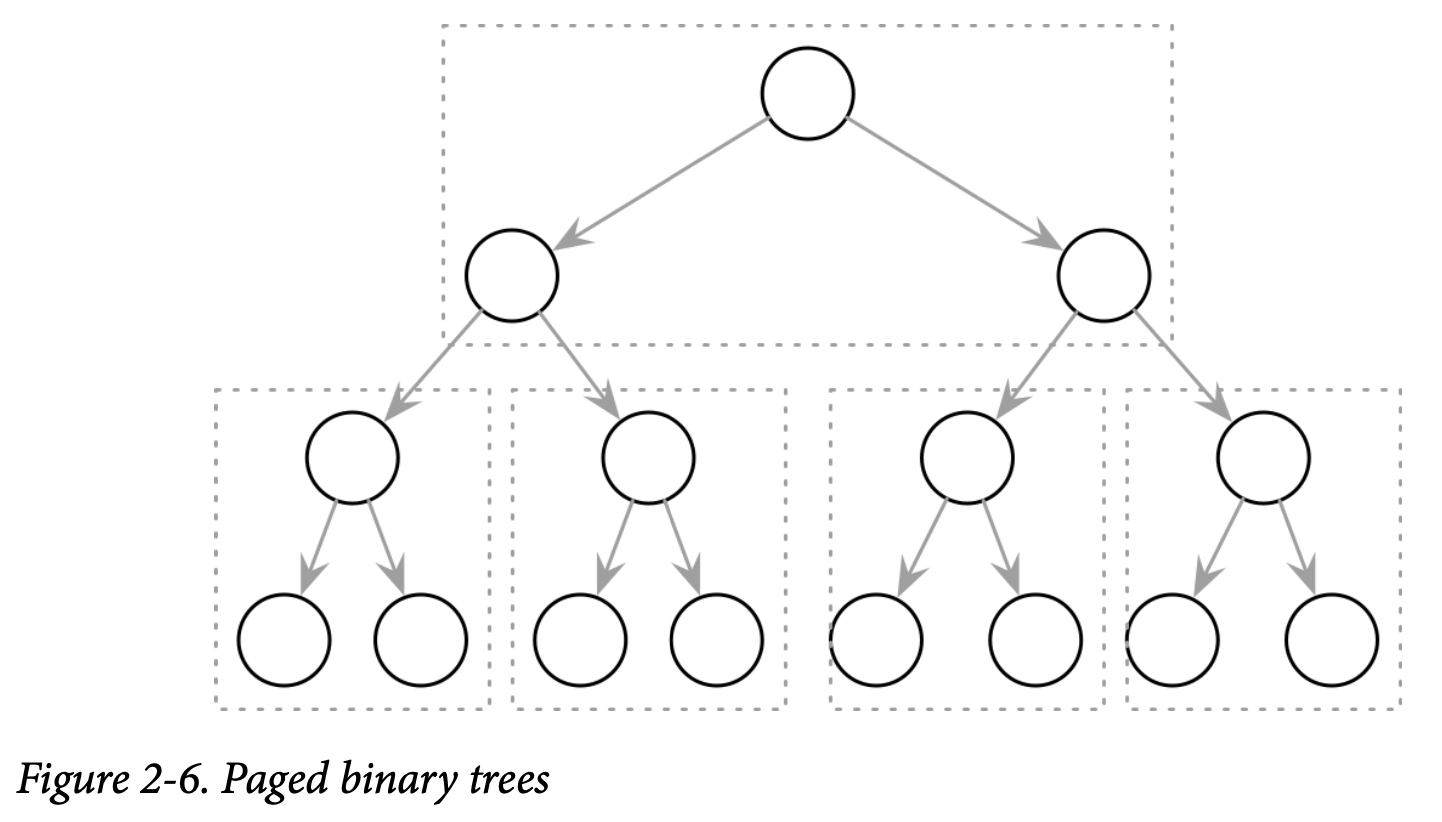
Paged Binary Trees
下图我们将二叉树的布局调整为将多个节点组合到同一个页上,如 Figure 2-6 所示,提高了数据的局部性。在需要查找下一个节点时,只需要在已经读取到内存的页中查找即可。但是任由一些额外的开销来自于节点跟指针之间。对存储在磁盘上的数据结构进行管理不是容易的事情,尤其是在 Key 跟 Value 不是以有序的方式添加的。平衡需要对页进行重建,这也会导致需要更新指针的信息。